
التعليقات المغلقة طريقة فعّالة لتحسين إمكانية الوصول، والتفاعل، والاحتفاظ بالمعلومات أثناء العروض التقديمية والفعاليات الحية.
تحويل النصوص التلقائية الكلام إلى نص يُظهر على الشاشة في الوقت الفعلي بنفس لغة الكلام. التعرف الآلي على الكلام (ASR) هو نوع من الذكاء الاصطناعي يُستخدم لإنتاج هذه النصوص المكتوبة للجمل المنطوقة.
معدل خطأ الكلمات
لتقييم دقة الترجمات التلقائية، المقياس الأكثر استخدامًا هو معدل الخطأ في الكلمات (WER). يقيس هذا عدد الأخطاء في النص التلقائي مقارنةً بالكلمات الفعلية التي ينطقها المتحدث. أساسًا، يوفر طريقة لتحديد مدى كفاءة النظام التلقائي في تحويل الكلام إلى نص.
على سبيل المثال، إذا كان 4 من كل 100 كلمة خاطئة، فإن الدقة ستكون 96٪.
معدل الخطأ في الكلمات (WER) هو مقياس يُستخدم لقياس دقة الترجمات التلقائية. يقوم بمواءمة سلاسل الكلمات المحددة بشكل صحيح على مستوى دقيق قبل حساب العدد الإجمالي للتصحيحات اللازمة لمواءمة النص المرجعي والنص المنسوخ بالكامل. يشمل ذلك تحديد الاستبدالات والحذف والإدراج. ثم يُحسب معدل الخطأ في الكلمات بقسمة عدد التعديلات المطلوبة على إجمالي عدد الكلمات في النص المرجعي. بشكل عام، كلما كان معدل الخطأ في الكلمات أقل، كلما كان نظام التعرف على الصوت أكثر دقة.
يتغاضى WER عن طبيعة الأخطاء
يمكن أن يكون قياس معدل الخطأ بالكلمة (WER) مضللًا لأنه لا يُخبرنا بمدى صلة/أهمية الخطأ المعين. الأخطاء البسيطة، مثل التهجئة البديلة لنفس الكلمة (movable/moveable)، لا يُنظر إليها غالبًا كأخطاء من قبل القارئ، بينما قد يكون الاستبدال (exemptions/essentials) أكثر تأثيرًا.
أرقام معدل الخطأ اللفظي، خاصةً في أنظمة التعرف على الكلام ذات الدقة العالية، يمكن أن تكون مضللة ولا تتطابق دائمًا مع تصورات البشر للصحة. بالنسبة للبشر، يكون من الصعب غالبًا التمييز بين مستويات الدقة التي تتراوح بين 90% و99%.
| النص الأصلي: | مخرجات ترجمات ASR: |
| على سبيل المثال، أنا أفعل أحب فقط الاستخدام المحدود للغاية لـ الأساسيات المقدمة أود أن أتعمق في نقطة معينة بمزيد من التفصيل أخشى أن أنا أدعو على برلمانات الدول الفردية لتصديق الاتفاقية فقط بعد توضيح دور المحكمة الأوروبية قد يكون له آثار ضارة جدًا. | على سبيل المثال، أود أيضًا أن يُستَخدم الاستثناءات المقدَّمة بشكل محدود جدًا فقط، وأرغب في الخوض في نقطة معينة بمزيد من التفصيل، أخشى أن النداء على برلمانات الدول الفردية لتصديق الاتفاقية فقط بعد توضيح دور المحكمة الأوروبية قد يسبب آثارًا ضارة جدًا. |
معدل الخطأ المتصوّر لـ Interprefy'
قامت Interprefy بتطوير مقياس خطأ ASR مملوك ومخصص للغة يُدعى WER المتصوّر. يحسب هذا المقياس فقط الأخطاء التي تؤثر على فهم الإنسان للكلام وليس جميع الأخطاء. عادةً ما تكون الأخطاء المتصوّرة أقل من WER، وأحيانًا تصل إلى 50٪. عادةً ما يكون WER المتصوّر بنسبة 5-8٪ غير ملحوظ تقريبًا للمستخدم.
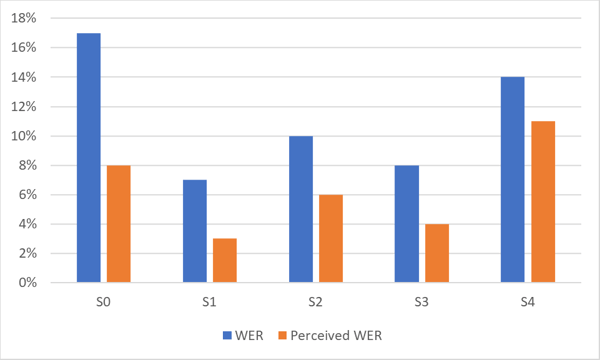
يوضح المخطط أدناه الفرق بين معدل خطأ الكلمات (WER) ومعدل خطأ الكلمات المتصوّر (Perceived WER) لنظام التعرف الصوتي عالي الدقة. لاحظ الاختلاف في الأداء لمجموعات البيانات المختلفة (S0‑S4) لنفس اللغة.
كما هو موضح في الرسم البياني، فإن معدل الخطأ المتصور من قبل البشر غالبًا ما يكون أفضل بكثير من معدل الخطأ الإحصائي.
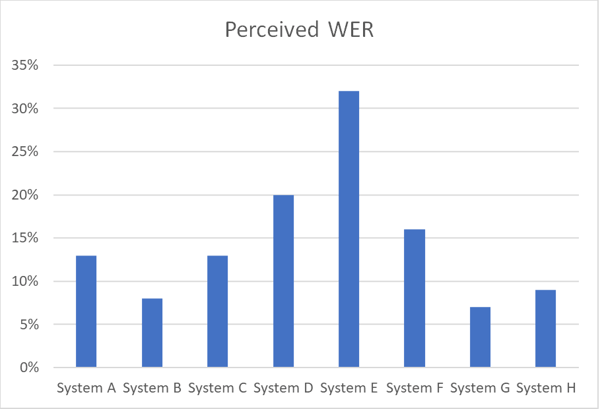
الرسم البياني أدناه يوضح الفروق في الدقة بين أنظمة التعرف على الكلام المختلفة التي تعمل على مجموعة بيانات الكلام نفسها بلغة معينة باستخدام معدل الخطأ المتصور.
العوامل الرئيسية لتحقيق ترجمات مغلقة دقيقة للغاية
هناك ثلاثة أمور رئيسية يجب أن تأخذها في الاعتبار:
- استخدم حلاً من الدرجة الأولى: بدلاً من اختيار أي محرك جاهز لتغطية جميع اللغات، اختر مزودًا يستخدم أفضل محرك متاح لكل لغة في فعاليتك.
- تحسين المحرك: اختر مزودًا يمكنه تعزيز الذكاء الاصطناعي بقاموس مخصص لضمان التقاط أسماء العلامات التجارية، والأسماء غير المعتادة، والاختصارات بشكل مناسب.
- تأكد من جودة إدخال الصوت: إذا كان إدخال الصوت سيئًا، لن يتمكن نظام التعرف على الكلام من تحقيق جودة الإخراج. تأكد من أن الكلام يمكن التقاطه بصوت عالٍ وواضح.